Data Consolidation
This article details the data consolidation process, exploring the steps involved in combining similar data from different resources and mapping source attributes to the attributes defined in the data models.
What is data consolidation?
Data consolidation refers to the process of combining data from multiple sources into a unified and consistent format. It involves gathering data from various systems, databases, or files and merging them into a single dataset. The purpose of data consolidation is to not only eliminate duplicates, but also create a comprehensive and integrated view of the information that can be easily analyzed and used for decision-making purposes.
Consolidation plays a crucial role in the data orchestration process within the Brinqa Platform. After individual source data models (SDM) have been created from imported data, consolidation combines identical data from multiple sources and maps them to the unified data models (UDM). To illustrate this process, the following diagram simplifies it using two sources, Tenable.io and Qualys Vulnerability Management (VM):
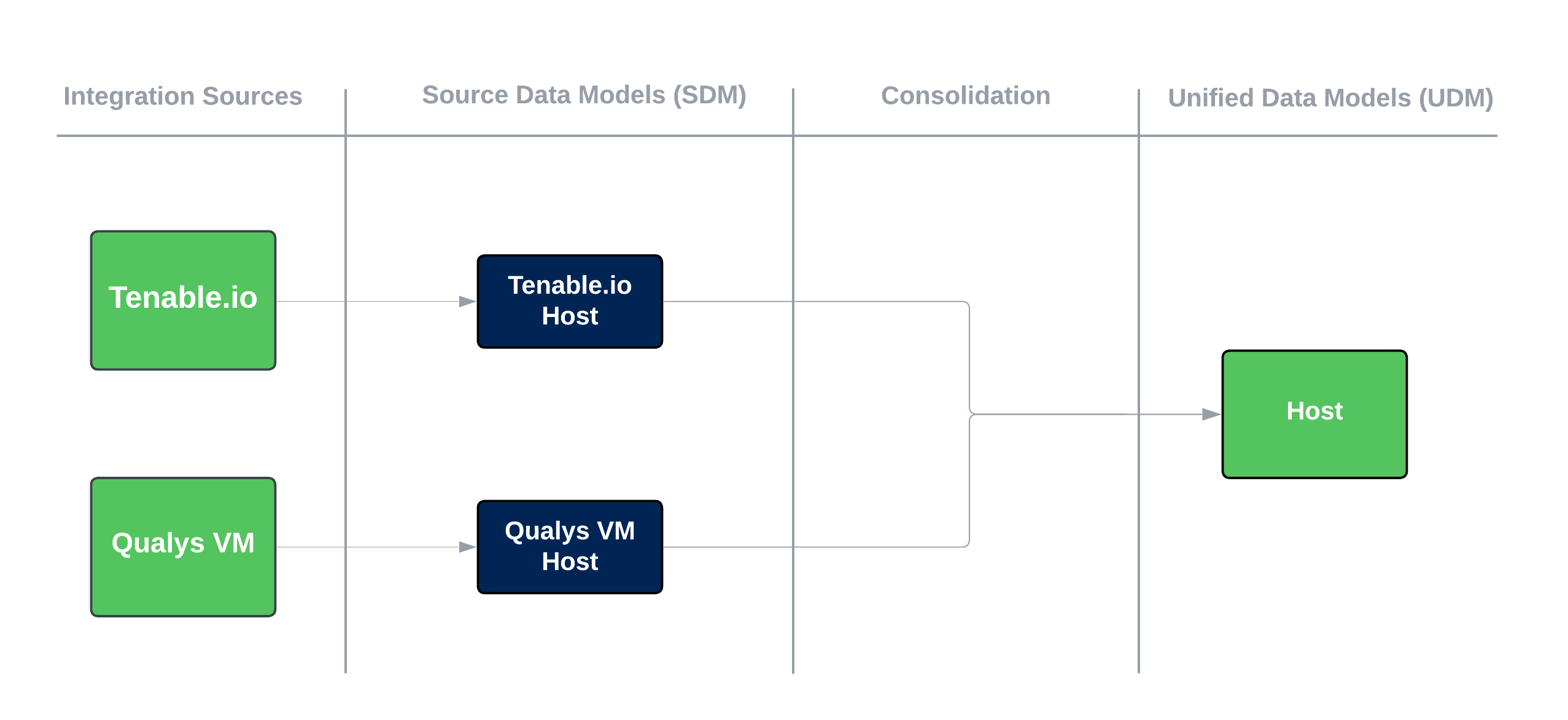
Figure 1. Multiple source data models consolidated into unified data models.
When examining host details on the Inventory > Hosts page (hold the pointer over the record and click Details), you can click the Sources tab to view how the specific host record has been consolidated. The following screenshot showcases a host record consolidated from four different sources:
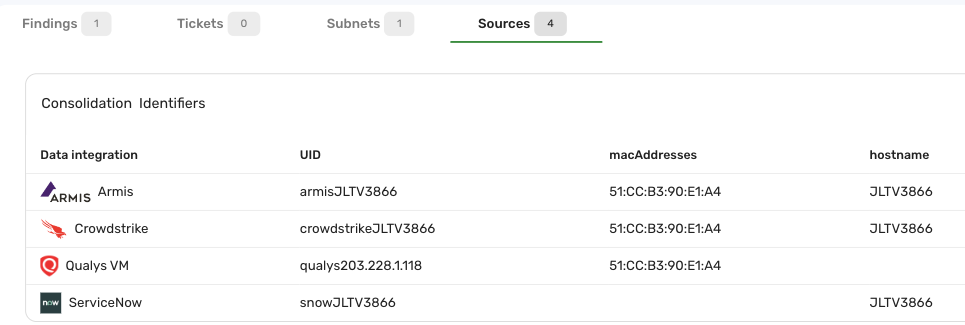
For this host record, while the UID value is different across all sources, the MAC address is the same for Armis, CrowdStrike, and Qualys VM. Similarly, the hostname value is identical for Armis, CrowdStrike, and ServiceNow. The data from these four sources have been merged into a unified entry in the Brinqa Platform, effectively eliminating any duplications.
How does data consolidation work?
In the Brinqa Platform, consolidation is configured in the data model, which serves as a template for the imported dataset. The Consolidation page, found within data models, offers two main functionalities:
-
Identifier designation: This feature lets you select and arrange the identifiers for data consolidation. By specifying which attributes serve as identifiers and in what order, you determine how data from different sources are combined and unified, thus eliminating duplicates.
-
Attribute mapping: This feature enriches the consolidated dataset by mapping attributes from different sources to corresponding attributes in the data model. This process ensures that the consolidated dataset incorporates relevant and comprehensive information. See Enrich data through attribute mapping for more information.
Achieve data deduplication through identifier designation
When importing data from various sources, it's typical to encounter overlapping information, such as identical MAC address or hostnames for a given host. To avoid importing duplicate datasets, Brinqa Integration+ connectors designate specific attributes as identifiers for data consolidation.
An identifier is a piece of information that uniquely identifies the host, regardless of the data source that provides the information. For example, the following screenshot showcases the Host data model in a test system. The data models listed under Sources are SDM created by the Brinqa Platform after importing from those data sources, and the identifiers are those used to consolidate the source datasets. The number displayed next to each identifier represents the count of SDM using this identifier. You can click the identifier to see which SDM is using it.
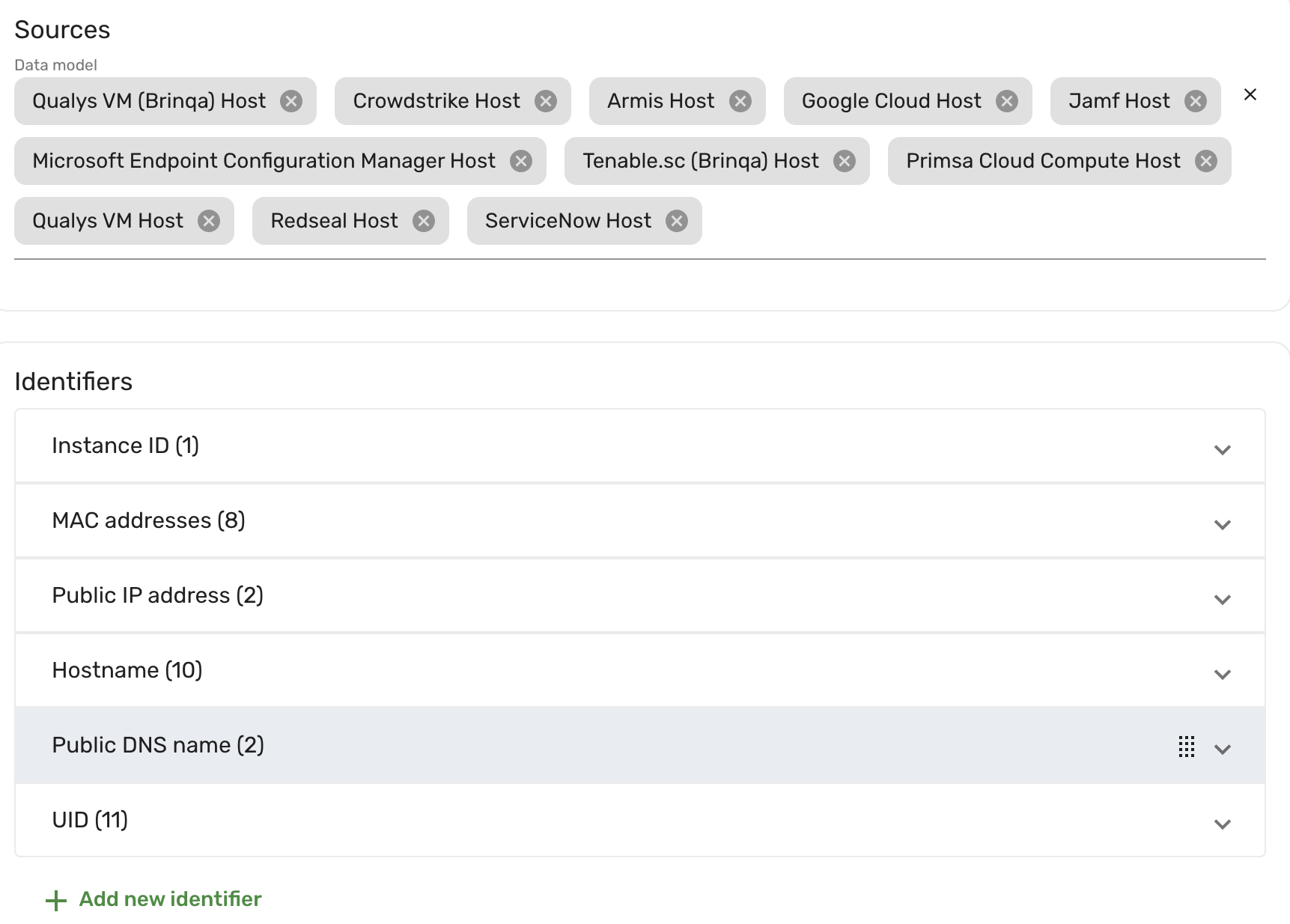
When importing data from each source, Brinqa follows a top-to-bottom order of precedence for evaluating identifiers. It stops the evaluation after a match is found. Referring to the screenshot above, Brinqa starts by evaluating the Instance ID identifier.
- If the instance ID of the incoming record matches that of an existing host, Brinqa consolidates the incoming record with the existing host and proceeds to the next record.
- If the instance ID doesn't match, Brinqa creates a new host record.
- If the instance ID is empty or missing from the incoming record, Brinqa then assesses the
MAC addressesidentifier in a similar manner, followed by thePublic IP address, and so on. If none of the identifiers yield a match, Brinqa creates a new host record.
Data consolidation is case sensitive by default. However, you can click the Ignore Case toggle to enable case-insensitive matching on a per-identifier basis.
For multi-value attributes such as MAC addresses, Brinqa goes through each value in the incoming record one by one looking for a match in an existing host. Again, this evaluation stops when a match is found, or if no matches are found, it proceeds to the next record.
If you have added or modified records manually, Brinqa adds an SDM named Manual entry to the list of sources for consolidation. By default, the Manual entry SDM takes precedence over other sources for identifier designation. In other words, Manual entry appears first in the drop-down list for each identifier. You can adjust the order if this doesn't align with your preference. See How are manual entries consolidated? for details.
Brinqa recommends that you always put UID as the last identifier as a catch-all mechanism since they tend to be unique in different sources.
Consolidation sequence and dependencies
Not all data models support consolidation out of the box. Parent data models, such as Asset, Finding, Finding Definition, or Ticket, lack the specificity to build the attack surface or comprehend the cybersecurity posture. Therefore, they don't support consolidation by default.
The following data models support consolidation out of the box:
-
Data models extending Asset: Account, Application, Certification, Cloud resource, Code project, Code repository, Container, Container image, Device, Host, Host image, IP range, Network segment, Package, Service, Site, Site certificate, and Subnet.
-
Data models extending Entity model: Assessment, Attack mitigation, Attack pattern, Attack tactic, Attack technique, Attack vector, Business service, Business unit, Company, CPE record, CVE record, EOL advisory, Installed package, Person, Remediation campaign, Security advisory, Team, Threat intelligence, and Weakness.
-
Data models extending Finding: Dynamic code finding, Manual finding, Open source finding, Pentest finding, Static code finding, Violation, and Vulnerability.
-
Data models extending Finding definition: Dynamic code finding definition, Manual finding definition, Open source finding definition, Pentest finding definition, Static code finding definition, Violation definition, and Vulnerability definition.
-
Data models extending Ticket: Dynamic code ticket, Manual ticket, Open source ticket, Pentest ticket, Static code ticket, Violation ticket, and Vulnerability ticket.
To find out if the data model supports consolidation, follow these steps:
-
Navigate to Administration
 > Data > Models.
> Data > Models. -
Locate the data model.
-
On the Overview page, check if the Supports consolidation option is selected.
If this option has been enabled, you should see Consolidation in the left menu.
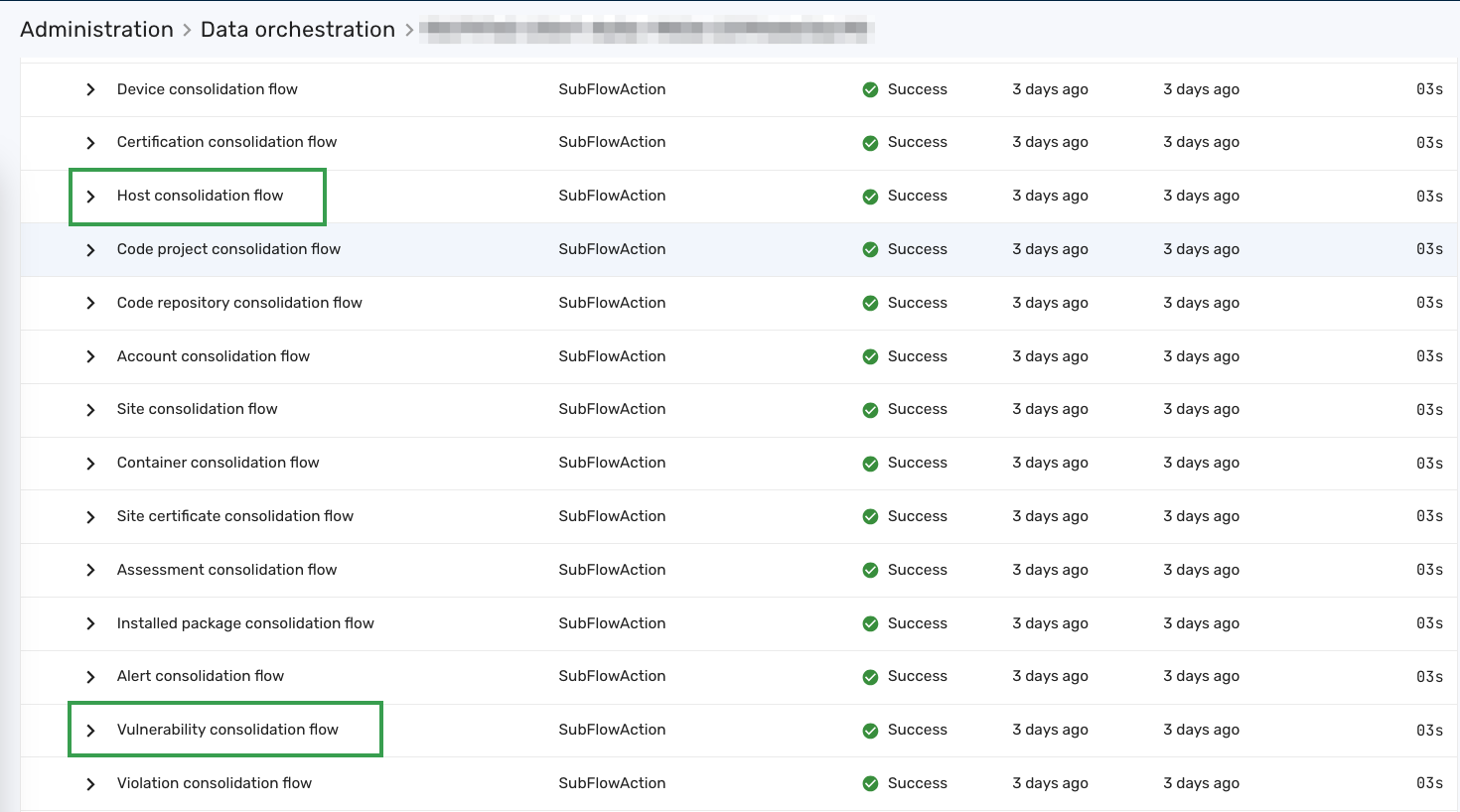
Since data models have attributes that are connected to other data models, certain data only becomes available or meaningful when other data is present. These dependencies dictate the sequence of the consolidation processes. During data orchestration, the Brinqa Platform runs consolidation following the order shown in the diagram, moving from left to right.

Figure 2. Data model consolidation sequence.
You can verify the sequence by visiting the Details page of an orchestration, under Data consolidation. Typically the Host consolidation flow runs before the Vulnerability consolidation flow because hosts provide the Targets attribute for vulnerabilities. If this order is changed—for example, the Host consolidation flow is cancelled and later rerun after the Vulnerability consolidation flow has already completed—the Targets attribute would be empty even though the host exists. This occurs because the host information isn't available when the vulnerability consolidation flow runs.
Deleting a data integration and its impact on consolidation
When you disable a data integration, the SDM records associated with that integration are not automatically updated. The consolidation process continues to run normally on all SDM data that is mapped to a UDM. Therefore, while the SDM records from the disabled integration remain unchanged, the consolidation process still operates based on the existing mappings and configurations. However, if you delete a data integration, the SDM records associated with that integration are removed and are no longer available for consolidation. Additionally, if you delete or disable a data integration, and you have a data lifecycle management policy enabled for that specific integration, the policy no longer runs.
Why are there still duplicates sometimes?
While Brinqa offers a predefined list of identifiers and their prioritized order, it may not align perfectly with the reliability and credibility of your specific data sources. Consequently, this misalignment can occasionally lead to duplication in the dataset. For example, if your machines can have multiple IP addresses but possess unique hostnames, using Brinqa's default order would result in duplicates because Public IP address is consolidated before Hostname. To address this issue, one possible solution is to move Hostname higher in the identifiers list.
Similarly, when multiple sources contain the same attribute, such as MAC address, there can be significant variations in the reliability and credibility of the source data. By default, Brinqa arranges the source attributes for each identifier according to the order of data integration creation. If CrowdStrike is consolidated before other sources, for example, but the data from CrowdStrike tends to be less reliable, your consolidated data may also become unreliable. To address this issue, you can move CrowdStrike lower in the attribute list for the MAC_ADDRESSES identifier or even remove it from the list entirely. This adjustment can help ensure that the consolidation is based on more dependable data sources.
Lastly, duplicate entries may arise from the quality of your data. For example, if a significant number of your host records lack hostnames, they will be consolidated together based on the Hostname identifier. To address this situation, either populate the hostnames for your records or move the Hostname identifier lower in the list. This adjustment can help mitigate the occurrence of duplicate entries.
How are manual entries consolidated?
If you modify a UDM record manually, Brinqa adds an SDM to represent your manual entries. The following screenshot shows the Sources tab of a host record that has been manually modified. Notice the source named Brinqa Manual Entry:
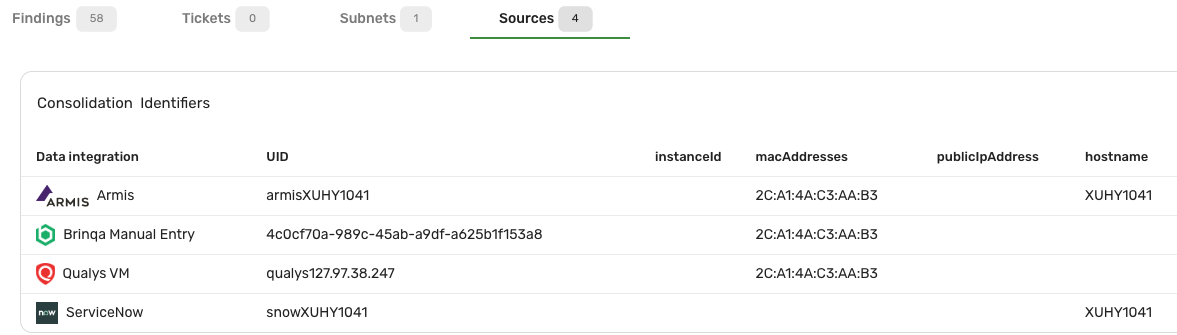
Manual entries undergo data orchestration as an SDM, thus they are evaluated against the same consolidation identifiers as the other sources. In this example, since the SDMs are first consolidated on the MAC_ADDRESSES attribute, the Brinqa Manual Entry adopts the same MAC address value, ensuring its consolidation into this UDM during subsequent orchestration processes.
To elaborate, suppose you want to add an Instance ID to this record, which is the first identifier evaluated for consolidation. You'll encounter an error upon saving your modification. This occurs because if the Instance ID field is updated with a new value, the Brinqa Manual Entry might merge with a different SDM when data orchestration runs, disassembling its consolidation.
Furthermore, you cannot modify the MAC_ADDRESSES field of this record either. This restriction is in place because if the MAC address value is updated or removed, the UDM will have to consolidate based on Public IP address, which is the next identifier on the list. And since it's empty, the consolidation would occur on Hostnames instead. In essence, this manual entry would no longer be consolidated on MAC_ADDRESSES, which is not allowed.
To maintain the integrity of the UDM, do not modify the attributes that have been used as consolidation identifiers.
Nevertheless, sometimes you might encounter an error, similar to the following, when trying to modify an attribute that isn't an identifier:

This error indicates that the identifier used by the record you're modifying is Hostnames, but the first identifier specified in the corresponding data model is UID, therefore your modification cannot be saved. (A manual entry automatically sets the UID field by default.)
There are multiple situations where this error may occur. One scenario is when the order of identifiers listed for the host record, which can be verified on the Sources tab, differs from the order specified in the Host data model. The Brinqa Platform detects the mismatch and issues the error. To resolve this issue, adjust the order of identifiers in the data model to align with the host record.
Changing the order of identifiers in the data model could impact manual entries and lead to the loss of your modifications to the original UDM. This could happen when the manual entry SDM is no longer consolidated with the original UDM due to the change of identifiers.
Should you need to rearrange the identifiers, make sure to run the consolidation flow afterward and update the manual entries accordingly.
You might encounter the aforementioned error in another scenario, where the manual entry uses a different attribute than the identifier. For example, in the following screenshot, the identifier is Instance ID, but the attribute of the manual entry is UID. This inconsistency is not supported and would lead to the previous error.
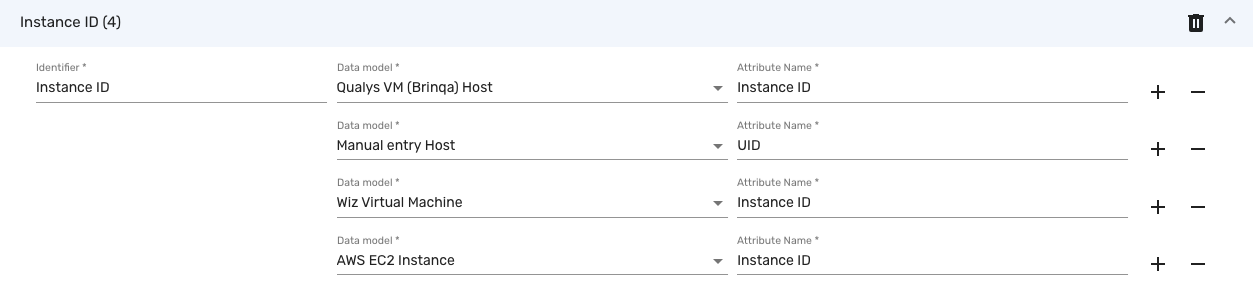
When setting up identifiers, the SDM attribute name must match the identifier, with the exception of case sensitivity.
Launch consolidation flows manually
If you have modified any consolidation settings in a data model, your changes will apply after the data orchestration runs. However, if you want the new consolidation to go into effect immediately, follow these steps:
-
Navigate to Administration
> Data > Models. -
Navigate to the data model you've modified the consolidation and click Flows.
-
Click the consolidation flow for your data model. For example, if you've modified the consolidation for the Host data model, click Host consolidation flow.
-
Click Launch, and then click Launch again in the confirmation dialog.
Tutorial: Consolidate a single SDM to multiple UDMs
You can consolidate a single SDM to multiple UDMs. For this tutorial, we have demonstrated how to manually map the Wiz Virtual Machine SDM to the Cloud Resource UDM.
While Integration+ connectors automatically create identifiers and map attributes, there may be cases where you need to manually define these mappings—for example, when consolidating a single SDM across multiple UDMs or when customizing attribute relationships to better fit your needs. The Wiz connector, for instance, automatically maps the Wiz Virtual Machine SDM to the Host UDM, but if you want to map it to another UDM, such as Cloud Resource, you need to manually define the identifiers and attribute mappings to ensure proper consolidation.
To consolidate the Wiz Virtual Machine SDM to the Cloud Resource UDM, follow these steps:
-
Navigate to Administration
> Data > Models. -
Locate the Cloud resource data model.
-
On the Cloud resource data model overview page, click Consolidation in the left menu.
-
Click the Sources field, type "Wiz Virtual Machine", and select Wiz Virtual Machine from the drop-down.
tipThe source name is case-sensitive.
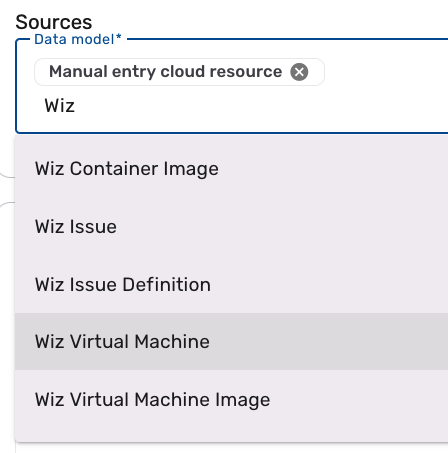
-
Go to the Identifiers section and select an identifier for your data. An identifier is a piece of information that uniquely identifies your data. For additional information on identifiers, see Achieve data deduplication through identifier designation.
-
Click UID and then click Add identifier.
-
In the new row, click the Data model drop-down and select Wiz Virtual Machine.
-
Click the Attribute Name drop-down and select UID.
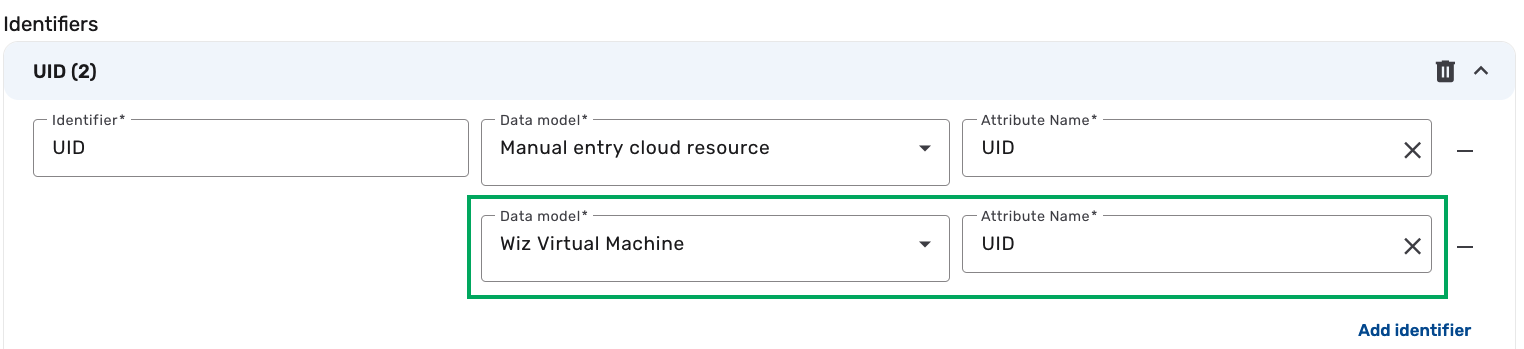 tip
tipFor this tutorial, we are using UID as the identifier. You can choose a different identifier and attribute based on your data model and consolidation needs. Name, Provider ID, and UID are commonly used identifiers for the Cloud Resource UDM.
-
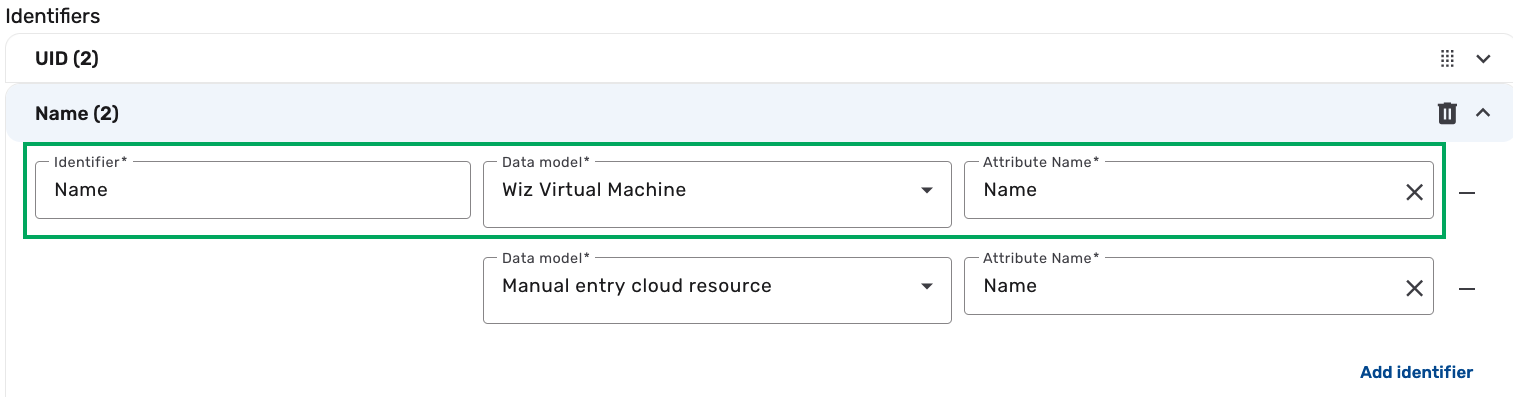
(Optional) You can also click Add new identifier to add a new identifier that is not already listed. For example, to also set Name as a possible identifier:
-
Click Add new identifier, and then type "Name" in the Identifier field.
-
Click the Data model drop-down and select Wiz Virtual Machine.
-
Click the Attribute Name drop-down and select Name.
 note
noteWhen adding a new identifier, you only need to configure it for the sources you want to consolidate using that identifier. If multiple data sources are mapped to the same UDM, such as Wiz Virtual Machine and Manual entry cloud resource as shown in the example, you must select each corresponding data model and its source attribute where this identifier should be applied. The number next to an identifier in the UDM indicates how many sources are using it.
-
-
Repeat the steps to add more identifiers.
-
-
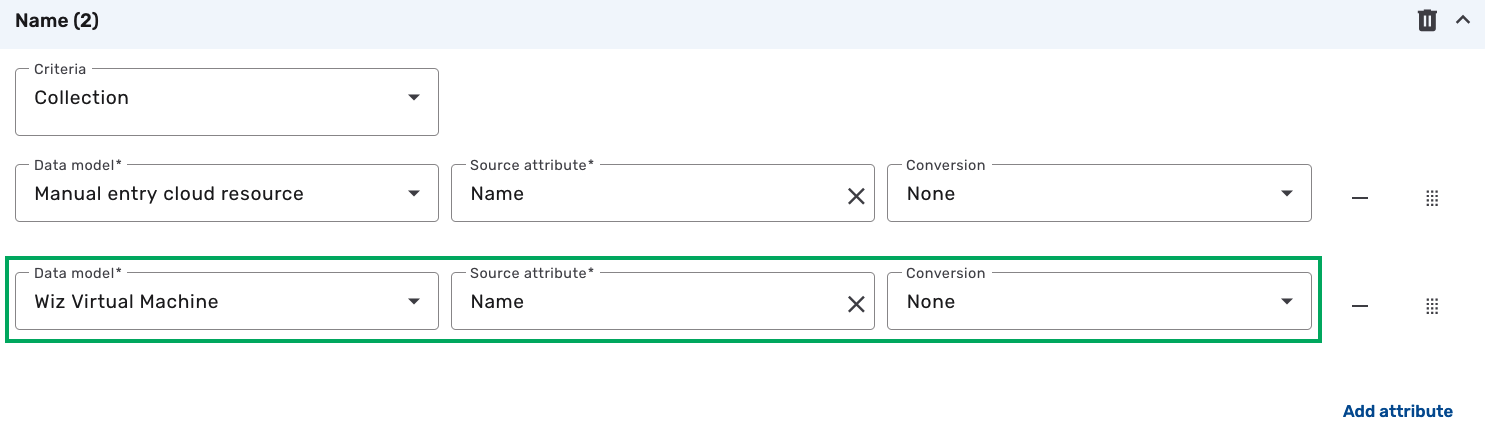
Go to the Attribute mappings section to add your mappings. Attribute mappings determine how data from the source model is assigned to attributes in the target UDM, ensuring that the correct values are retained during consolidation. For additional information, see Enrich your data through Attribute Mapping.
-
Click Name and then click Add attribute.
-
Leave the Criteria field as is, which collects all names. For additional information on mapping criteria, see Mapping criteria.
-
Click the Data model drop-down and select Wiz Virtual Machine.
-
Click the Source attribute drop-down and select Name.
-
Leave the Conversion field as is to indicate that no conversion is needed. For additional information on conversions, see Data conversions.
-
Repeat the steps to add more mappings. For this tutorial, add the following additional mappings:
- Categories ~ Categories
- Cloud provider ~ Cloud Platform
- Description ~ Description
- First seen ~ FirstSeen
- IP Addresses ~ IP Addresses
- Resource type ~ Resource Type
-
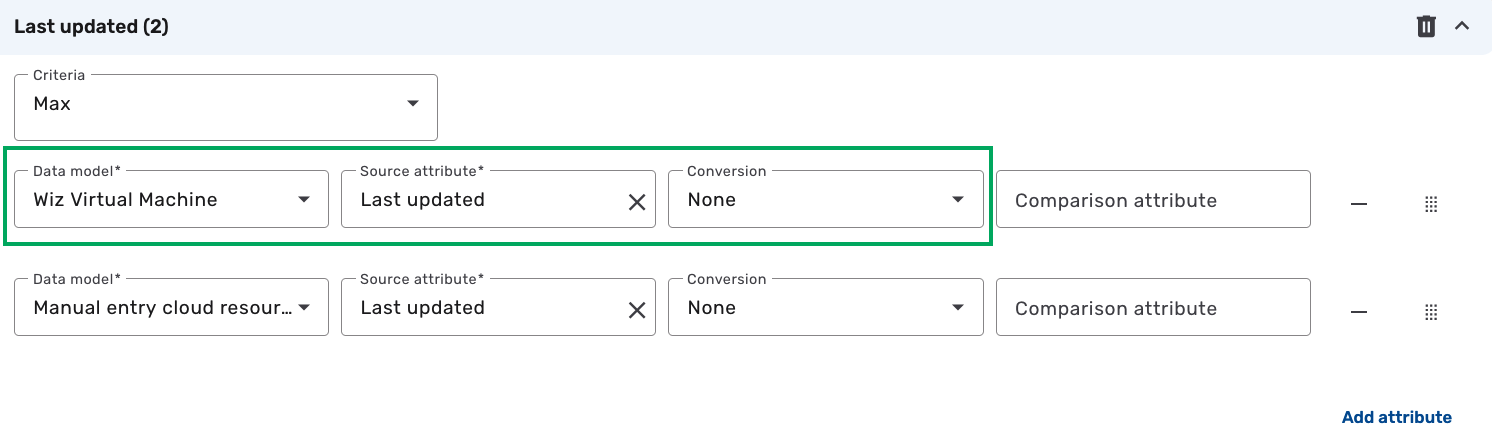
(Optional) You can also click Add new mapping to add a new attribute mapping that is not already listed. For example, to create a new attribute mapping for the Last updated field:
-
Click Add new mapping, search for "Last updated" and click it to select the attribute.
-
Click the Criteria drop-down and select Max, which ensures that the most recent Last updated value from all sources is stored. For additional information on mapping criteria, see Mapping criteria.
-
Click the Data model drop-down and select Wiz Virtual Machine.
-
Click the Source attribute drop-down and select Last updated.
-
Leave the Conversion field as is to indicate that no conversion is needed. For additional information on conversions, see Data conversions.
-
Leave the Comparison attribute field blank so the Max criteria is performed on the Last updated attribute.
-
-
-
Go to the bottom of the page and click Update.
You can wait for the daily orchestration to process your data, or run a sub-flow to see the result right away.
-
For the latter, click Flows in the left menu.
-
Click Cloud resource consolidation flow, click Launch, and then click Launch again.
This process runs data consolidation and incorporates the Wiz Virtual Machine data with the Cloud resource UDM.
-
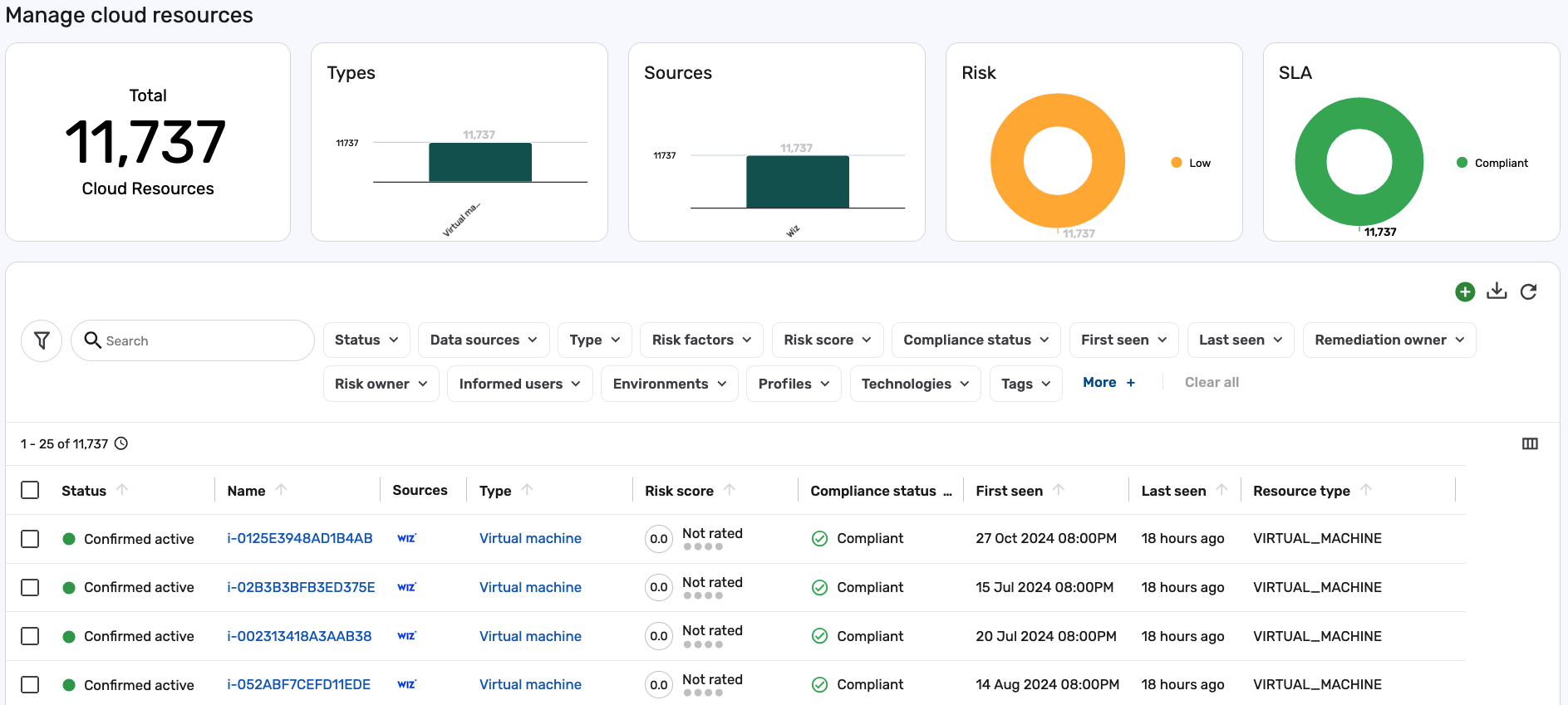
After the flow has completed, navigate to Inventory > Cloud > Cloud resources.
-
Search for any of your known Wiz Virtual Machines to ensure that the data is consolidated and the attributes are mapped properly.
For this tutorial, no cloud resources were present in the Brinqa Platform:
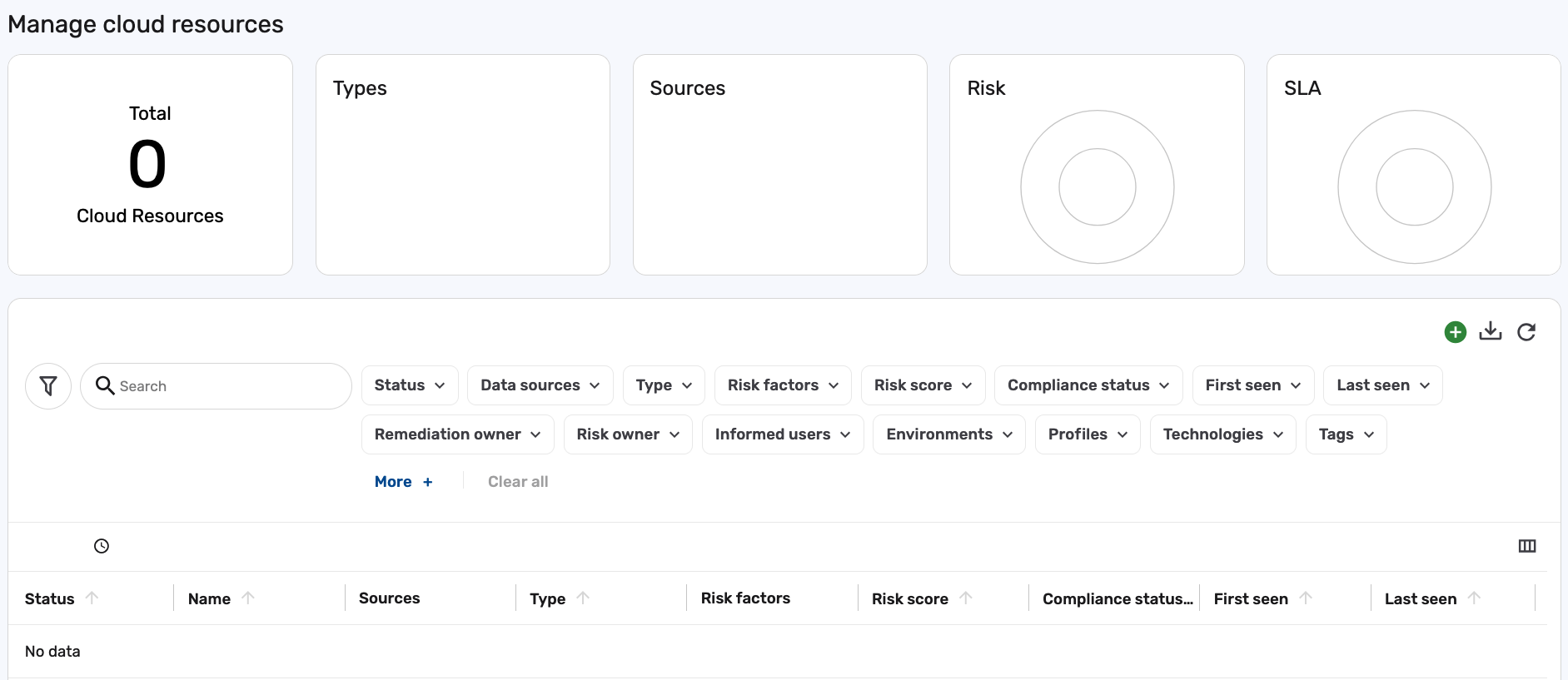
After performing the manual consolidation and attribute mappings, Cloud resources are now successfully populated:
 info
infoYou can follow the same approach to map Wiz Virtual Machines, or any SDM, to other UDMs as needed.