Calculated Attributes
This article details calculated attributes in Brinqa and the best practices when creating or updating them.
What are calculated attributes?
Brinqa provides the ability to compute attributes on the data model and calls them calculated attributes.
A calculated attribute can be any of the supported attribute types in a data model. It can be a text attribute, a numeric attribute, or a reference attribute. The main difference is that a calculated attribute executes a script to compute the value of the attribute.
For example, the Data model name attribute in the Entity Model is a calculated (text) attribute:
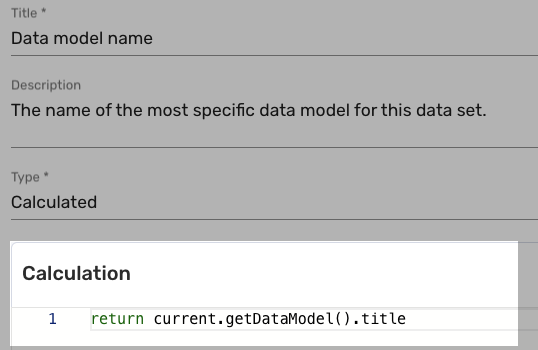
It returns the title of the data model of the current record. The current record can be the Entity Model or whichever data model that extends the Entity Model, making this code flexible and easy to maintain.
Calculation scripts
The scripts in calculated attributes are written in Groovy, a powerful programming language for the Java platform. The rest of this article assumes that you are familiar with the Groovy programming language. Please refer to the Apache Groovy Documentation if you need help on the specification.
Calculation process
The calculation process consists of two steps: reading from the Neo4j database and writing to it. Neo4j issues shared locks for read transactions and exclusive locks for write transactions, there can be multiple holders of a read lock, but only one holder of a write lock. Reading and writing at the same time generally ends in lock contention, so Brinqa separates the reading process from writing to avoid locking.
Read records and run calculations
The reading process includes the following steps:
-
Load (or read) batches of records from Neo4j.
-
Run calculations on batches of records in parallel and temporarily store the results on the file system.
Write to the database using the temporarily stored results
The writing process includes the following steps:
-
Write primitive types (such as integral types, boolean types, or char types) to records in Neo4j.
-
Write reference types to records in Neo4j.
-
Send out changes to the Audit channel for logging.
Best practices for calculated attributes
Now that you have learned what calculated attributes are and what the calculation process involves, Brinqa recommends the following best practices when creating or updating calculated attributes:
Always include a comment section to clearly outline the objective of the script or function.
For example:
/*
* Set the status of the findings to inactive
* @param arguments is a map that contains all variables returned from the function GET_INACTIVE_FINDINGS
* @param stepName is the name of the step from where you are getting the data
* @return does not return anything as it only sets the status in the database
*/
def SET_INACTIVE_FINDINGS(Map arguments, String stepName) {
Do not hardcode any unique identifiers in your scripts. Hardcoding the id attribute makes code sharing and maintenance difficult. Use the name attribute instead, which is always indexed.
- Bad example:
Long dataModelId = 124546454575DataModel dm = DataModel.get(dataModelId)
- Good example:
String dataModelName = 'Finding'DataModel dm = DataModel.find("match(a:CI__DataModel) where a.name = \$dataModelName return a", [dataModelName: dataModelName])
Attribute calculation should not take longer than 10 milliseconds in the worst-case scenario. If you cannot improve the calculation further, consider using a flow instead.
You can pull the performance metrics on calculated attributes via the Brinqa Platform API. To do so, follow these steps:
-
Copy the
access_tokenfield from the output. The token is valid for 24 hours. -
Pull the performance metrics.
Type the following command and press Enter:
curl 'https://<your-brinqa-platform-url>/v1/api/metrics/compute' \-s \-H 'Accept: application/json' \-H "Authorization: Bearer <your-access-token>" \| jq -r '.scripts[] | keys[] as $k | "\(.[$k] | .snapshot.median), \($k)"' \| sort -nrReplace
<your-access-token>with theaccess_tokenyou have copied andyour-brinqa-platform-urlwith the URL of your Brinqa Platform.This command returns the median of the process time for each calculated attribute. The first column shows the time in nanoseconds. For example:
9570789, brinqa.compute.Host.owners8042103, brinqa.compute.Vulnerability.dueDate7400546, brinqa.compute.Vulnerability.sla7291202, brinqa.compute.VulnerabilityDefinition.riskFactorOffset7139361, brinqa.compute.Violation.sla6872467, brinqa.compute.ViolationDefinition.riskFactorOffset6551048, brinqa.compute.Package.owners6505069, brinqa.compute.DynamicCodeFinding.sla6459287, brinqa.compute.Certification.owners6309260, brinqa.compute.VulnerabilityTicket.slaDefinition5354951, brinqa.compute.Weakness.riskFactors5177999, brinqa.compute.Violation.displayName4983849, brinqa.compute.Vulnerability.baseRiskScore4971826, brinqa.compute.Vulnerability.displayNameIf you want to limit the output to a data model, for example, Vulnerability, you can add a
grepto your command:curl 'https://<your-brinqa-platform-url>/v1/api/metrics/compute' \-s \-H 'Accept: application/json' \-H "Authorization: Bearer <your-access-token>" \| jq -r '.scripts[] | keys[] as $k | "\(.[$k] | .snapshot.median), \($k)"' \| grep Vulnerability \| sort -nr
Always run your calculation against a small sample set first to assess its performance impact. Do not run the calculation on the entire data model until it has met the aforementioned performance criteria.
You can use a flow to trigger calculations on a limited dataset. Launch the flow after you have created or updated the calculated attribute, and then pull the performance metrics (as detailed in the previous bullet point) to see how long it takes to process your attribute.
Add all calculation functions to the user defined library (UDL) to avoid duplicate coding. (You can visit the UDL by navigating to Administration ![]() > Scripts > User defined libraries.) Your scripts should always call the UDL to get the desired output.
> Scripts > User defined libraries.) Your scripts should always call the UDL to get the desired output.
For example, the Host library has a baseRiskScore function:
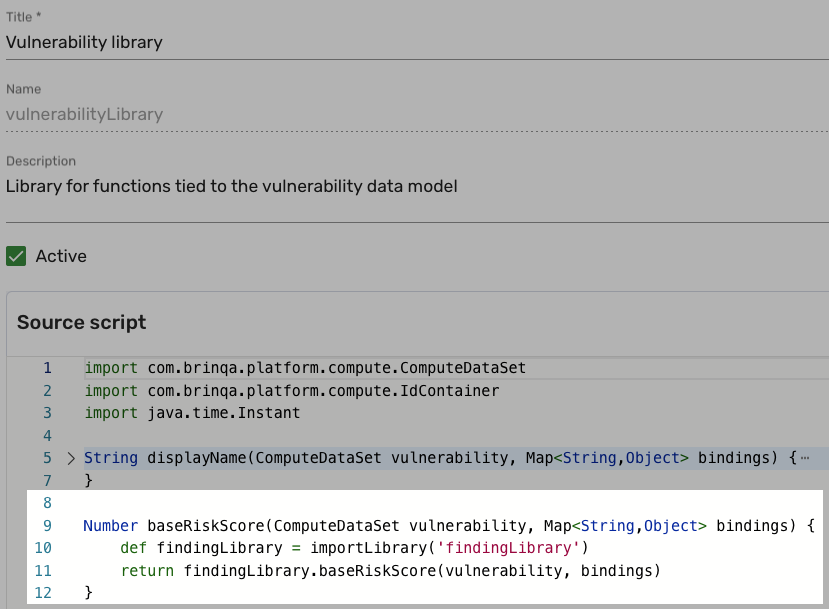
The Base risk score attribute in the Host data model calls this function in its calculation:
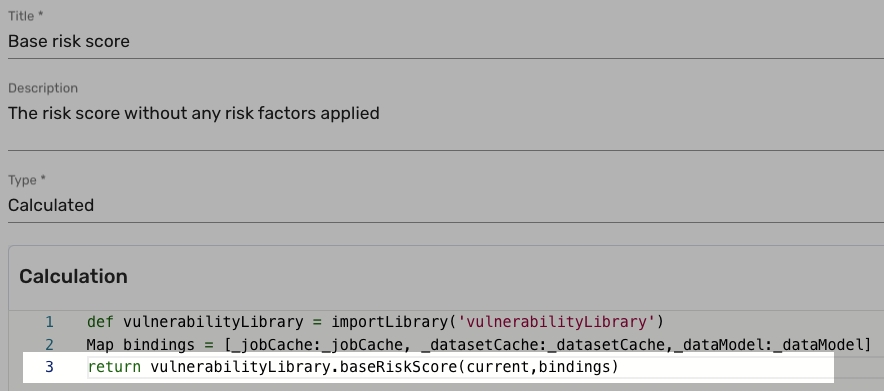
Do not return dates that constantly change because it results in a loop and endlessly recalculates.
For example, the following scripts are invalid:
-
return new Date()returns a new value every time the instance is updated or recalculated. -
return current.lastUpdatedreturns a different value every time as thelastUpdatedtimestamp is modified on every recalculation.
Do not use GString because it slows down your calculations.
For example, consider the following two scripts:
-
return "${current.firstName} ${current.lastName}" -
return current.firstName + ' ' + current.lastName
The first script runs much slower because it uses GString.
Do not use non-existent attributes in your scripts.
For example, if you use current.foo to store a value temporarily, where foo is not an attribute in the data model. Your Brinqa instance will load all the attributes from the database, one at a time, trying to find a match. Such operations often result in long-running queries. And if you need to use the value more than once, you incur the penalty for each lookup.
Therefore, Brinqa recommends that you use the following function to store the value for the lifetime of the record:
_datasetCache.computeIfAbsent('<key>') { <expensive operation> }
This function first performs a lookup in memory to see if <key> has been populated in the cache. If it has not, the function executes the <expensive operation> to populate the cache entry and returns the result. Since the result is stored in memory, the subsequent lookups are fast. Using this function guarantees that the <expensive operation> only executes once no matter how many times its result is needed.
Use _jobCache to share information across records, especially when one of the record sets is large.
For example, when performing calculations on vulnerabilities, which frequently exceeds 100,000 records, you often need to know the type of the vulnerability. The Type attribute in the Vulnerability data model references another data model - Vulnerability definition. Since many vulnerabilities are of the same type, you can use a job cache to hold all the necessary information from the vulnerability definition.
Create a flow to trigger calculations on a limited dataset
If you have created or updated a calculated attribute, Brinqa recommends that you assess its performance impact using a small sample set. You can create a flow to trigger calculations on a limited set of records. To do so, follow these steps:
-
Navigate to Administration
 > Automation > Flows.
> Automation > Flows. -
Click View all next to Recent folders or Recent flows, click New, and then select Instant - from blank from the dropdown.
-
Enter the following name and description, select a folder for the flow, and then click Create.
-
Name: Calculation Trials
-
Description: This flow is used to trigger calculations on a limited dataset to verify performance
-
-
The JavaScript Object Notation (JSON) code displays. Replace the existing code with the following:
{
"actions": {
"BRINQA_FLOW_END_STEP": {
"@type": "noop"
},
"computeInstances": {
"@type": "compute",
"attributeNames": [],
"batchSize": 100,
"failureThresholdPercentage": 0,
"inputArgument": "instances",
"notify": false,
"propagate": false,
"reindexBehavior": "REINDEX_UPDATED"
},
"failure": {
"@type": "slack",
"messageTemplate": "{\"text\":\"Failure of the workflow.\"}",
"webhookUrl": "/SLACKWEBHOOKURL/"
},
"loadInstances": {
"@type": "cypherDataProvider",
"batchSize": 10000,
"query": "MATCH (v:Finding) return v.id as id limit 1000",
"resultKey": "instances",
"storageBufferSize": 5000
}
},
"active": true,
"arguments": {},
"categories": [],
"description": "This flow is used to trigger calculations on a limited dataset to verify performance",
"name": "calculationTrials",
"steps": [
{
"actionReference": "loadInstances",
"arguments": {},
"name": "loadInstances",
"retryCriteria": {
"@type": "transient"
},
"retryPolicy": {
"@type": "none"
},
"timeoutInSeconds": 60000,
"title": "Load instances",
"transition": {
"failure": "failure",
"@type": "static",
"success": "computeInstances"
}
},
{
"actionReference": "computeInstances",
"arguments": {},
"name": "computeInstances",
"retryCriteria": {
"@type": "transient"
},
"retryPolicy": {
"@type": "none"
},
"timeoutInSeconds": 60000,
"title": "Compute instances",
"transition": {
"failure": "failure",
"@type": "static",
"success": "BRINQA_FLOW_END_STEP"
}
},
{
"actionReference": "BRINQA_FLOW_END_STEP",
"arguments": {},
"name": "BRINQA_FLOW_END_STEP",
"retryCriteria": {
"@type": "transient"
},
"retryPolicy": {
"@type": "none"
},
"timeoutInSeconds": 10,
"title": "BRINQA_FLOW_END_STEP",
"transition": {
"@type": "end"
}
},
{
"actionReference": "failure",
"arguments": {},
"name": "failure",
"retryCriteria": {
"@type": "transient"
},
"retryPolicy": {
"@type": "none"
},
"timeoutInSeconds": 10,
"title": "failure",
"transition": {
"@type": "end"
}
}
],
"template": false,
"title": "Calculation Trials",
"trigger": {
"@type": "manual",
"description": "Manual Trigger"
}
}
If you need to change the data model or the size of your dataset, modify the query attribute, change Finding to the data model of your choice, and limit 1000 to the appropriate size.
Do not go beyond 100,000 records when conducting a performance evaluation.